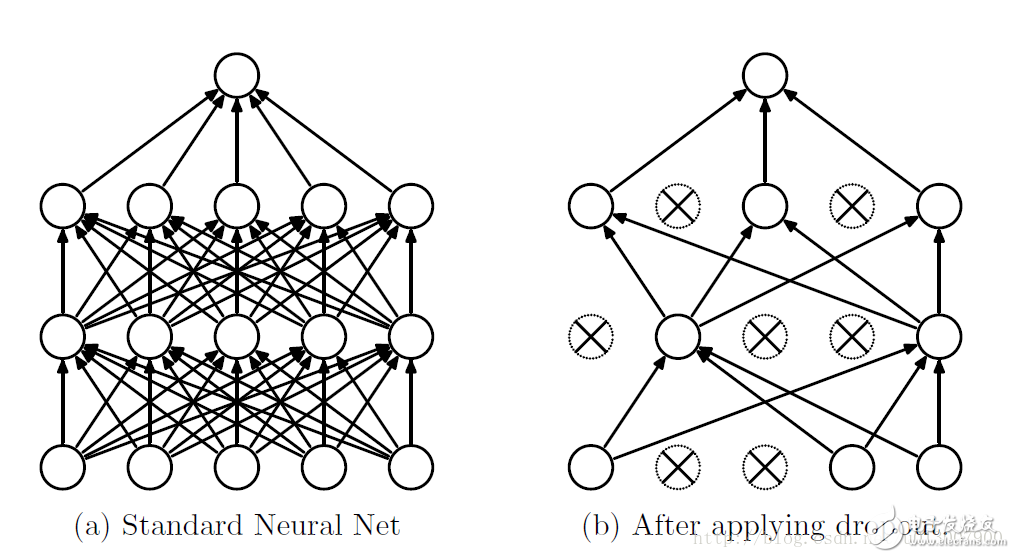
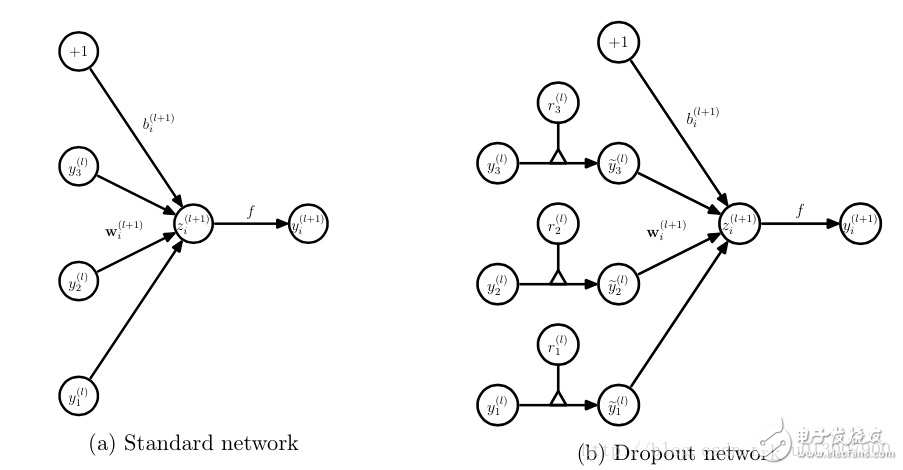
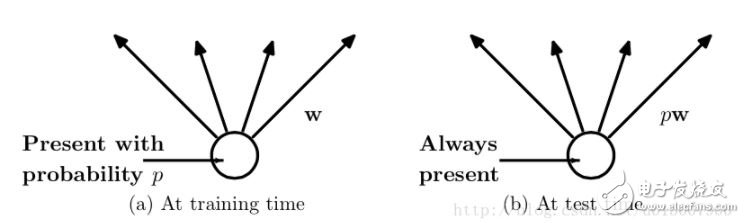
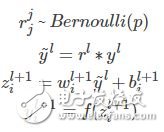Dropout refers to the temporary discarding of neural network units from the network according to a certain probability during the training of the deep learning network. Note that for the time being, for random gradient descent, each mini-batch is training a different network because it is randomly discarded. Overfitting is a common problem in deep neural networks (DNN): the model only learns to classify on the training set, and many solutions to overfitting problems proposed in these years, where dropout is simple and works very well. Algorithm overview We know that if you want to train a large network, and the training data is very small, then it is easy to cause over-fitting. In general, we will think of regularization or reduce the network scale. However, Hinton's 2012 document: "Improving neural networks by prevenTIng co-adaptaTIon of feature detectors" proposes that at the time of each training, half of the feature detectors are randomly stopped, which can improve the generalization ability of the network. Hinton calls it dropout again. The first way to understand is to use dropout at each training session. Each neuron has a 50% probability of being removed, so that one neuron's training does not depend on another neuron. Synergies between features are attenuated. Hinton believes that overfitting can be alleviated by preventing the synergy of certain features. The second way to understand is that we can think of dropout as a way to average multiple models. For reducing errors in the test set, we can average the predictions of multiple different neural networks. Because of the randomness of the dropout, the network model can be regarded as a neural network with different structures after each dropout. The number of parameters to be trained is constant, which frees the time-consuming problem of training multiple independent neural networks. When testing the output, divide the output weight by two to achieve a similar average effect. It should be noted that if dropout is used, the training time is greatly extended, but it has no effect on the test phase. Training process with dropout In order to achieve the characteristics of ensemble, with the dropout, the neural network training and prediction will change. Here is the use of dropout to discard neurons with the probability of p Training level The corresponding formula changes as follows: Neural network without dropout Neural network with dropout Inevitably, each unit of the training network adds a probabilistic process. Test level When predicting, the parameters of each unit are premultiplied by p. In addition to this, there is another way to keep the forecasting phase unchanged while the training phase changes. I have checked a lot of information about this ratio, the previous is the conclusion of the paper; followed by the implementation of dropout in the keras source. There are inconsistencies in the formulas written by blogs. I wrote a version that I think is correct. Dropout and other regularizations Dropouts typically use L2 normalization and other parameter constraint techniques. Regularization helps keep small model parameter values. After using Inverted Dropout, the above equation becomes: It can be seen that with Inverted Dropout, the learning rate is scaled by the factor q=1−p. Since q is between [0, 1], the ratio between η and q changes: References refer to q as a driving factor because they enhance the learning rate and call r(q) an effective learning rate. The effective learning rate is higher relative to the selected learning rate: normalization based on this constraint parameter value can help simplify the learning rate selection process. Improving neural networks by prevenTIng co-adaptaTIon of feature detectors Improving Neural Networks with Dropout Dropout: A Simple Way to Prevent Neural Networks from Overtting ImageNet Classification with Deep Convolutional
Engine drive Pump:
. Pump driven by diesel engine directly
. Pump driven by gas engine directly
. Water pump stantion
. Oil pump station
Engine Pump,Gas Engine Pump,Engine Driven Pump,Diesel Engine Pump Guangdong Superwatt Power Equipment Co., Ltd , https://www.swtgenset.com